An essay from July ’17, originally published on the TechStars Medium channel, that looks at the first two years of SV. At that time I had seen 170 prototypes leveraging AI/ML and MPP databases.
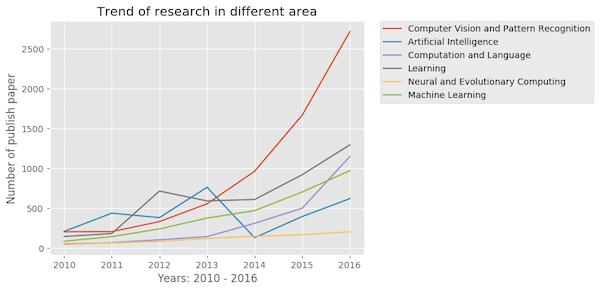
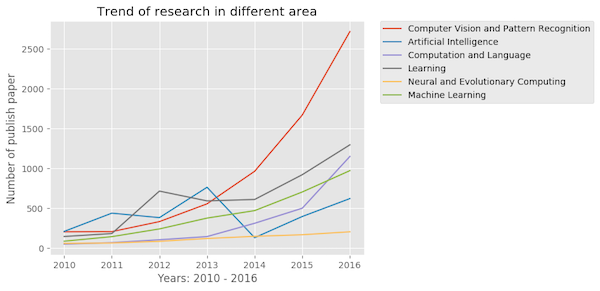
Number of published papers in selected AI fields on ArXiv ; source: https://neelshah18.github.io/Scopus-analysis.html
Here is an Exec Summary of what I had learned at that stage:
- Research-driven teams are increasingly players in the startup space. ArXiv acts as a motivating example to push new models of know-how sharing.
- Despite this, most research based startups still function as outsourced research teams for corporates.
- To reach product/market fit, they first need to focus on time to data and iterate faster before they start testing data acquisition strategies.
The accidental benefits of helping research-driven prototypes become startups
Two years ago, a friend gave me the push I needed to walk into the selection day of the initial Techstars Berlin cohort as a mentor. As a Techstars mentor ever since, I’ve continued to help “deep tech” (in my case, specifically Massively Parallel Processing (MPP) database, Artificial Intelligence (AI) / Machine Learning (ML) and open source enterprise) startups go from prototype to product-market fit. That first day at the Techstars Berlin class I met the Rasa team — fast forward to today where I am both an investor and operational advisor with Rasa. Rasa is now the leading open source conversational AI software on the market, with thousands of companies using its initial NLU tool, launched last December.
However, Rasa is the exception and the vast majority of startups I engage with are still at the prototype stage. Prototypes, by definition are not finished.
Prototypes are not ready for VCs. However, building something new is much more valuable for startups than presentations or market research can be. The experience of seeing tens of prototypes in particular category hit road blocks or thrive, is the primary source of learning for my evolving investment theses.
Singularity isn’t near, but specialised apps are
For example it feels as though there is not a day that goes by without a proponent of singularity — the point in history when general purpose A.I. surpasses human intelligence, leading to an unimaginable revolution in human affairs. That singularity is close by. On the other hand our own user experience with first generation chatbots could be interpreted to suggest that none of that is even remotely close. Looking under the hood, one sees that only a couple of tens of bots are not rule-based. In contrast, the best of the over 170 prototypes I have seen in the last two years are debunking the myth of a superhuman AI and are specialised applications in specific industry verticals that outperform humans at very specific and narrowly defined tasks.
Platforms won’t eat it all
Another very popular argument is to suggest the big (US and Chinese) internet platforms will essentially “own” multi-industry A.I. markets because “A.I. is an industry in which strength begets strength: The more data you have, the better your product; the better your product, the more data you can collect.” This is true to a certain extent for application in image recognition, self-driving cars, speech-to-text, and basically anything where everyone tends to agree on the ‘right’ answer. But there is not always just one answer. If, however you are trying to build something new with ML, or learn something new about your data by applying it, then this is a completely different game. There will be many vertical winners.
In addition, an important aspect of the data argument is much, much weaker than the debate suggests.
The prototypes I see show me that training neural nets on past data has very limited value.
It may help to speed up initial prototypes, but that’s about it. Large corporations may have logs of years and years of consumer data and interaction, but when they start training neural nets they have to start from scratch. The playing field is surprisingly level for startups. I don’t think many in the Fortune 500 have realised that AI means that much of the data they sit on is worth much less than they think.
Beyond that, looking at the teams I have met, there’s two main trends I have seen: For one, these research-driven teams, often inspired by the community engagement around scientific paper platform ArXiv, are now getting into the startup scene. Most of times they function as small, outsourced research-driven teams for corporates.
1. ArXiv-inspired, research-driven teams, are getting into the startup scene
This level playing field may also be one reason why so many research-driven teams are getting into the (Berlin) startup scene.
It’s new for Berlin. The Berlin startup scene has long been a destination for entrepreneurial business students that fostered what is locally called ‘operational’ startups. Rocket Internet was built on their talent and the opportunities around exploiting existing technology opportunities in markets disregarded by the Valley. Many of these opportunities now appear to be exhausted. Research-driven startups, like my own Xyo, have been an exception so far. What’s less known is that the city also always had large independent developer scenes. But these devs either worked at corporations and did some hobby work on the side or were contractors at established companies living in Berlin. Circumstantially, back in 2011 I remember Reto Meier from the Android team invited me to attend an Android event in Berlin with +1500 devs. Outside of me there was not a single person from the local startup scene attending, just these hobby developers.
This is still true. PhDs still mostly go into German corporates (engineering, banking, finance, Mittelstand). But we now have a new steady stream of research-driven founders. Additionally, many of them come from outside of Berlin. More than 60% of the 170 teams we met came outside of Berlin (we have meet with teams with PhDs from Cambridge, London, Edinburgh, Potsdam, Tübingen, Karlsruhe, Zürich, Warsaw). Prototype tourism from the US and Asia is alive and kicking as well. Supporting a 3 person team on just €4k a month for 6 months in a global city is hard to beat.
The rise of the ArXiv-inspired Startup
I have been told time and again that another motivator for research-driven teams to get into startups is that startups are now a great space for applied research — a notion that research in startups allows for greater levels of freedom than in corporates.
Open know-how sharing, discussion and debate, as well as quick cycles of open-source adoptions (almost immediately published on Github) make startups, from afar, seem very attractive to researchers. Online forums and platforms have been big in pushing this idea and no other company has played such a role than ArXiv, Cornell University’s popular online repository of scientific papers, and various group chats. The way some of the researchers live-tweet their ideas/research and engage openly is super inspiring for these researchers. It often creates the (misguided) assumption that startups will give researchers freedom they would not otherwise have with a university or corporate overhead. Frequently AI teams just publish research and never build a product or business, rather just wait to get acquired.
Let’s take an early example, visual style transfers, that got exposure by the popularity of the Prisma app, an app that allows to transfer the style of one image to the subject of another image.
Originally, a group of researchers associated with the Bethgelab at the University of Tübingen did the research and published the paper, A Neural Algorithm of Artistic Style, back in September ‘15.
The research got picked up immediately and collaboration on the paper’s application started a couple of days later on Github. Related popular papers and applications sprang up shortly after and continue to do so until today. By June ’16 the Prisma app was launched by couple of Russian boys and the related work hit the awareness of a wider public once the Prisma apps hit their Facebook feeds.
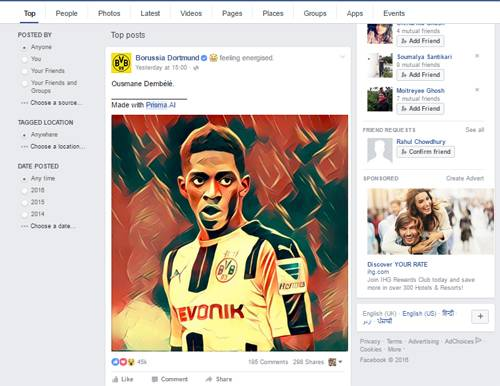
What’s been widely acknowledged is that the wide-spread of Prisma images made the general public curious about what neural nets can do. But there’s also been an effect the other way, from the startups to public to the research community.
Suddenly, to many it felt as if startups are an option to take the work to. Eventually, the Bethelab group created a Prisma style website, too. I have met over 15 startups whose ideas at least partly on ArXiv papers. Many more I talked to credit ArXiv as the place where they got their conviction to try out startups.
It’s the rise of the Arxiv-inspired startup as Robbie Allen notes:
“The key that makes AI different than most other technologies is its strong research background. (…) Instead of keeping innovation closed or waiting until the final moment once an idea has been fully baked and lots of code written, most research is based on a few months worth of work and limited code. The point is to get the ideas out to the community as quickly as possible so others can improve on them (and you get credit for the idea before someone else does).”
The Limits of ArXiv-inspired Startups
In the meantime AI research and progress continue on ArXiv, not only in style transfers, but vision and image modelling (image recognition, visual question answering, image semantic labelling, video recognition, generation of images) in particular. The level of activity and openness is lesser in written and spoken language research and even less so in ML systems learning.
There’s no one in language who live-tweets their ideas/ research the way Alex Champandard or Nicholas Guttenberg do, for example. Also language is complicated because it’s more tribal. There’s a crowd that thinks deep learning will just solve NLP and you won’t need to know anything about language any more. Then there are the computer linguists who get annoyed at computer vision / deep learning people who do a little experiment with text data and make ‘big’ claims that they’re solving problems in NLP, which they aren’t.
2. Most common: the small, outsourced research-driven teams for corporates
A large challenge for many of these teams to become startups remains. Some of these challenges are ‘normal’ in the startup world and many of the questions these teams should ask themselves are also similar.
There’s also some specific patterns. Over 90% of AI prototypes we have seen have enterprise-centric and not consumer-centric. As these teams bootstrap, most of them target a few large (paying) corporations as clients.
In this sense, they are much better described as ‘outsourced research agencies for corporates’ than ‘VC-grade startups’ with potential for exponential growth. That’s not a bad thing to start with and dig deeper into a problem. In 2017 there’s an ample supply of corporates out there engaging with startups. Here in Berlin alone we have over 160 corporate accelerators and innovation arms. That’s a lot of potential local cheques to pay the bills early on.
Here’s an example. One of the startups that I saw recently was working with two makers of IoT fridges. Essentially, once the fridge door closes, a camera inside takes a picture of what’s inside. Some of the products can be identified by barcodes, some of them can not. The (daily-generated) data is then sent to the corporate for analysis.
Not surprisingly, this is where the fuzzy promise of “big data” broke down for the corporate.
The corporate could not figure how to tackle the ETL problems and make sense of the data in-house. Enter our startup of researchers. At the time I met them, the startup had come up with a lot of great stuff on how to tackle many of the challenges. One of it was a fascinating model that managed to train a neural net to identify brand logos from images similar to this recently published work and then build some analysis functionality on top.

Pretty rad for a research-driven team to get to this point and be able to pay their bills from their work. But, just to re-iterate a previous argument, this achievement does not qualify them as a “startup” for VCs.
It could become a startup in future, but at this point it’s more of an early prototype with many holes in their stack and some initial agency-type clients. As others such as Eyeem’s Ramzi Rizk argued: becoming an AI startup in a VC model is much tougher.
Next: Time to data & faster Iterations
How do these small outsourced research agencies evolve to startups? There’s two immediate items they tend to tackle next.
Time to data
As Rasmus Rothe from AI venture builder Merantix says:
“In the academic world of machine learning, there is little focus on obtaining datasets. Instead, it is even the opposite: in order to compare deep learning techniques with other approaches and ensure that one method outperforms others, the standard procedure is to measure the performance on a standard dataset with the same evaluation procedure. However, in real-world scenarios, it is less about showing that your new algorithm squeezes out an extra 1% in performance compared to another method. Instead it is about building a robust system which solves the required task with sufficient accuracy. As for all machine learning systems, this requires labeled training from which the algorithm can learn from.”
In fact one might hypothesize that the key algorithms underlying AI breakthroughs are often latent, simply needing to be mined out of the existing literature by large, high-quality datasets and then optimized for the available hardware of the day as others have noted.
In my conversations I often advise theses agency types to run tests in a cohorted approach.
Keep the corporate paying clients to pay the bills.
But spend the same amount of time on servicing other clients.
The single item to optimise for in these “other” clients is the time to obtain data. A bonus goes to those who are also willing to test their crappy beta prototypes and give feedback. This often leads to initial cohorts with other startups (for “free”) and later cohorts with much smaller, often founder-led enterprises that can take decisions without a formal purchase process overhead.
Faster Iteration cycles
The other piece of advice is around ad-hoc data analysis. It’s about finding out which models work, the patterns that work for that specific data set.
This means, that the team won’t be operating at scale with millions of data points, it will be operating at 3000 or 10000 data sets. Instead it will be looking at the data and seek patterns.
A simple and cheap way to handle this is to do some serverless Mysql queries on an AWS S3 bucket or build up something simple on top of Redshift. With this teams can dump a bunch of data into AWS without building any infrastructure so they can run sql queries and see what they can find.
At this point the team will spend much more time cleaning their data (between 70% to 90% of their time), then some time in finding the patterns and the smallest amount of time in building the algorithms. This is counter-intuitive for most research-y startups. Preferably, though, the team will be moving to its next cohort iteration within two or three weeks — and not months as previously.
 source: https://twitter.com/msukmanowsky/status/885870033108422656
source: https://twitter.com/msukmanowsky/status/885870033108422656Once one finds a cohort of interest, one can look into startup data acquisition strategies and investigate their viability. Figuring out these data strategies is possibly the largest counter-intuitive challenge for research-driven teams.
In fact, some of these strategies can be controversial and make the team truly re-think what startups are. Take the example of Babylon Health, a chatbot app where users can ask questions about their condition without having to visit a GP and which recently raised $60M. It argues that “Babylon scientists predict that we will shortly be able to diagnose and foresee personal health issues better than doctors.” In the Western world there’s all kinds data, science & legal problems and for commercialization when one goes from diagnostic to predictive health.
Purely from a tech perspective, health team often can come up with a measure that detects or predict a particular issue better than a human. Going from 30% to 60% accuracy can be, in theory, be spectacular and save many lives. But getting sued by the 40% can brake the startup. That’s why, many health teams run their early cohorts in countries with weak data protection / low downsides of being sued. Babylon Health, for example, has 450,000 users in Rwanda. Related teams in predictive health in the Western World go through corporations to deal with regulated health systems.
A research-driven team, at this stage, needs to have become a data-driven team as well.
Data is not democratic (yet?)
Not surprisingly, people with interest in fostering startup AI innovation such Zeroth.ai’s Tak Lo identify “a data divide is the greatest threat to innovation in AI” and call for democratization of data.
Tak’s call for an open Wikipedia-type AI database also implies that perhaps the major challenge for AI teams lies in data access. Founders arguing to build domain-specific products in verticals such as legal tech or Fintech the platforms such Google or Microsoft don’t care about as much about this, to a lesser extent, as well.
But data, overall, is not democratic. Despite recent initial noise around platform efforts around it and also vertical app stores such as Helix being launched — AI has not had the “App Store moment” that fostered the democratization of development and distribution mobile has had (yet).
We are only at the beginning
This is a great time for research-driven teams to prototype their ideas and test out the startup world. As we see more and more of them, ArXiv’s role in facilitating will surely also increase. Many of them will be working as outsourced research teams for corporates and that’s already a stand alone achievement. Some of them will go even further: figure out their product-market fit, as well as their data acquisition strategies and go onto change the world.